概要此线程池拥有一个被所有工作线程共享的任务队列。线程池用户提交的任务,被线程池保存在任务队列中,工作线程从任务队列中获取任务并执行。 任务是可拥有返回值的、无参数的可调用(callable)对象,或者是经 std::bind 绑定了可调用对象及其参数后的调用包装器。具体而言可以是 - 自由函数(也称为全局函数)
- lambda
- 函数对象(也称为函数符)
- 类成员函数
- 包装了上述类型的 std::function
- bind 调用包装器
该线程池异步地执行任务。当任务被提交进线程池后,用户不必等待任务执行和返回结果。 ◆ 实现以下代码给出了此线程池的实现,(lockwise_shared_pool.h) class Thread_Pool { private: struct Task_Wrapper { ... }; atomic<bool> _done_; // #2 Lockwise_Queue<Task_Wrapper> _queue_; // #3 unsigned _workersize_; thread* _workers_; // #4 void work() { Task_Wrapper task; while (!_done_.load(memory_order_acquire)) { if (_queue_.pop(task)) task(); else std::this_thread::yield(); } } void stop() { size_t remaining = _queue_.size(); while (!_queue_.empty()) std::this_thread::yield(); std::fprintf(stderr, "\n%zu tasks remain before destructing pool.\n", remaining); _done_.store(true, memory_order_release); for (unsigned i = 0; i < _workersize_; ++i) { if (_workers_[i].joinable()) _workers_[i].join(); } delete[] _workers_; } public: Thread_Pool() : _done_(false) { // #1 try { _workersize_ = thread::hardware_concurrency(); // #5 _workers_ = new thread[_workersize_]; for (unsigned i = 0; i < _workersize_; ++i) { _workers_[i] = thread(&Thread_Pool::work, this); // #6 } } catch (...) { stop(); // #7 throw; } } ~Thread_Pool() { stop(); } template<class Callable> future<typename std::result_of<Callable()>::type> submit(Callable c) { // #8 typedef typename std::result_of<Callable()>::type R; packaged_task<R()> task(c); future<R> r = task.get_future(); _queue_.push(std::move(task)); // #9 return r; // #10 } };折叠
我们从构造 Thread_Pool 对象(#1)开始了解这个线程池。atomic<bool> 数据成员用于标志线程池是否结束,并强制同步内存顺序(#2);Task_Wrapper 具体化了线程安全的任务队列 Lockwise_Queue<>(#3);thread* 用于引用所有的工作线程对象(#4)。Task_Wrapper 和 Lockwise_Queue<> 稍后再做说明。 线程池通过 thread::hardware_concurrency() 获取当前硬件支持的并发线程数量(#5),并依据此数量创建出工作线程。Thread_Pool 对象的成员函数 work() 作为所有工作线程的初始函数(#6),这使得线程池中的任务队列能被所有工作线程共享。创建 thread 对象和 new 操作可能失败并引发异常,因此用 try-catch 捕获潜在的异常。处理异常过程中,需要标志线程池结束,保证任何创建的线程都能正常的停止,并回收内存资源(#7)。线程池对象析构时的工作与此一致。 Thread_Pool 对象构建完成后,任务通过 Thread_Pool::submit<>() 被提交进入线程池(#8)。为了支持任务的异步执行,任务先被封装在 std::packaged_task<> 中,再被放入线程安全的任务队列(#9)。任务执行结果被封装在返回的 std::future<> 对象中(#10),允许用户在未来需要结果时,等待任务结束并获取结果。 因为每一个任务都是一个特定类型的 std::packaged_task<> 对象,为了实现任务队列的泛型化,需要设计一个通用的数据结构 Task_Wrapper,用于封装特定类型的 std::packaged_task<> 对象,(lockwise_shared_pool.h) struct Task_Wrapper { struct Task_Base { virtual ~Task_Base() {} virtual void call() = 0; }; template<class T> struct Task : Task_Base {
std::packaged_task<> 的实例只是可移动的,而不可复制。Task_Wrapper 必须能移动封装 std::packaged_task<R()> 对象(#1)。为了保持一致性,Task_Wrapper 也实现了移动构造(#2)和移动赋值(#3),同时实现了 operator()(#4)。ABC 的继承结构(#5)用于支持泛型化地封装和调用 std::packaged_task<> 对象。std::packaged_task<> 封装在派生类 Task<> 中(#6),由指向非泛型的抽象基类 Task_Base 的指针引用派生类对象(#7)。对 Task_Wrapper 对象的调用由虚调用(#8)委托给派生类并执行实际的任务(#9)。 另一个关键的数据结构是非阻塞式的队列 Lockwise_Queue<>,(lockwise_queue.h) template<class T>class Lockwise_Queue { private: struct Spinlock_Mutex { // #3 atomic_flag _af_; Spinlock_Mutex() : _af_(false) {} void lock() { while (_af_.test_and_set(memory_order_acquire)); } void unlock() { _af_.clear(memory_order_release); } } mutable _m_; // #2 queue<T> _q_; // #1 public: void push(T&& element) { // #4 lock_guard<Spinlock_Mutex> lk(_m_); _q_.push(std::move(element)); } bool pop(T& element) { // #5 lock_guard<Spinlock_Mutex> lk(_m_); if (_q_.empty()) return false; element = std::move(_q_.front()); _q_.pop(); return true; } bool empty() const { lock_guard<Spinlock_Mutex> lk(_m_); return _q_.empty(); } size_t size() const { lock_guard<Spinlock_Mutex> lk(_m_); return _q_.size(); } };
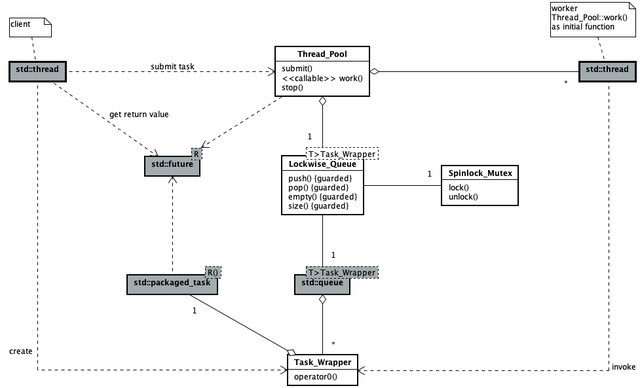
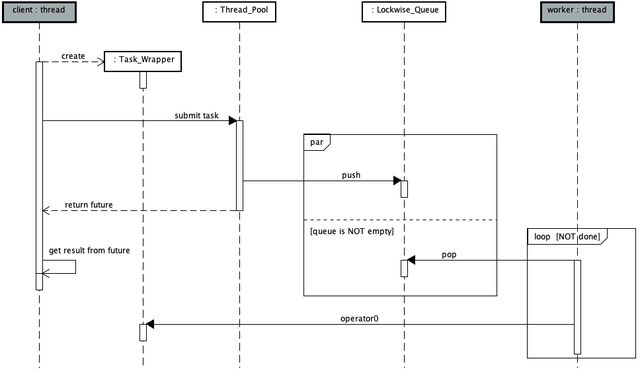
所有 Task_Wrapper 对象保存在 std::queue<> 中(#1)。互斥元控制工作线程对任务队列的并发访问(#2)。为了提高并发程度,采用非阻塞自旋锁作为互斥元(#3)。任务的入队和出队操作,分别由支持移动语义的 push 函数(#4) 和 pop 函数(#5)完成。 ◆ 逻辑以下类图展现了此线程池的代码主要逻辑结构。 [注] 图中用构造型(stereotype)标识出工作线程的初始函数,并在注解中补充说明此关系。 以下顺序图展现了线程池用户提交任务与工作线程执行任务的并发过程。 ◆ 验证为了验证此线程池满足概要中描述的能力,设计了如下的各可调用对象,(archery.h) void shoot() { std::fprintf(stdout, "\n\t[Free Function] Let an arrow fly...\n");} bool shoot(size_t n) { std::fprintf(stdout, "\n\t[Free Function] Let %zu arrows fly...\n", n); return false;} auto shootAnarrow = [] { std::fprintf(stdout, "\n\t[Lambda] Let an arrow fly...\n");}; auto shootNarrows = [](size_t n) -> bool { std::fprintf(stdout, "\n\t[Lambda] Let %zu arrows fly...\n", n); return true;}; class Archer { public: void operator()() { std::fprintf(stdout, "\n\t[Functor] Let an arrow fly...\n"); } bool operator()(size_t n) { std::fprintf(stdout, "\n\t[Functor] Let %zu arrows fly...\n", n); return false; } void shoot() { std::fprintf(stdout, "\n\t[Member Function] Let an arrow fly...\n"); } bool shoot(size_t n) { std::fprintf(stdout, "\n\t[Member Function] Let %zu arrows fly...\n", n); return true; } };
对这些函数做好必要的参数封装,将其提交给线程池,(test.cpp) minutes PERIOD(1);size_t counter[11];time_point<steady_clock> start;atomic<bool> go(false); { Thread_Pool pool; thread t1([PERIOD, &counter, &start, &go, &pool] { // test free function of void() while (!go.load(memory_order_acquire)) std::this_thread::yield(); void (*task)() = shoot; for (counter[1] = 0; steady_clock::now() - start <= PERIOD; ++counter[1]) { pool.submit(task); //pool.submit(std::bind<void(*)()>(shoot)); std::this_thread::yield(); } }); thread t2([PERIOD, &counter, &start, &go, &pool] { // test free function of bool(size_t) while (!go.load(memory_order_acquire)) std::this_thread::yield(); bool (*task)(size_t) = shoot; for (counter[2] = 0; steady_clock::now() - start <= PERIOD; ++counter[2]) { future<bool> r = pool.submit(std::bind(task, counter[2])); //future<bool> r = pool.submit(std::bind<bool(*)(size_t)>(shoot, counter[2])); std::this_thread::yield(); } }); thread t3([PERIOD, &counter, &start, &go, &pool] { // test lambda of void() while (!go.load(memory_order_acquire)) std::this_thread::yield(); for (counter[3] = 0; steady_clock::now() - start <= PERIOD; ++counter[3]) { pool.submit(shootAnarrow); std::this_thread::yield(); } }); thread t4([PERIOD, &counter, &start, &go, &pool] { // test lambda of bool(size_t) while (!go.load(memory_order_acquire)) std::this_thread::yield(); for (counter[4] = 0; steady_clock::now() - start <= PERIOD; ++counter[4]) { future<bool> r = pool.submit(std::bind(shootNarrows, counter[4])); std::this_thread::yield(); } }); thread t5([PERIOD, &counter, &start, &go, &pool] { // test functor of void() while (!go.load(memory_order_acquire)) std::this_thread::yield(); Archer hoyt; for (counter[5] = 0; steady_clock::now() - start <= PERIOD; ++counter[5]) { pool.submit(hoyt); std::this_thread::yield(); } }); thread t6([PERIOD, &counter, &start, &go, &pool] { // test functor of bool(size_t) while (!go.load(memory_order_acquire)) std::this_thread::yield(); Archer hoyt; for (counter[6] = 0; steady_clock::now() - start <= PERIOD; ++counter[6]) { future<bool> r = pool.submit(std::bind(hoyt, counter[6])); std::this_thread::yield(); } }); thread t7([PERIOD, &counter, &start, &go, &pool] { // test member function of void() while (!go.load(memory_order_acquire)) std::this_thread::yield(); Archer hoyt; for (counter[7] = 0; steady_clock::now() - start <= PERIOD; ++counter[7]) { pool.submit(std::bind<void(Archer::*)()>(&Archer::shoot, &hoyt)); //pool.submit(std::bind(static_cast<void(Archer::*)()>(&Archer::shoot), &hoyt)); std::this_thread::yield(); } }); thread t8([PERIOD, &counter, &start, &go, &pool] { // test member function of bool(size_t) while (!go.load(memory_order_acquire)) std::this_thread::yield(); Archer hoyt; for (counter[8] = 0; steady_clock::now() - start <= PERIOD; ++counter[8]) { future<bool> r = pool.submit(std::bind<bool(Archer::*)(size_t)>(&Archer::shoot, &hoyt, counter[8])); //future<bool> r = pool.submit(std::bind(static_cast<bool(Archer::*)(size_t)>(&Archer::shoot), &hoyt, counter[8])); std::this_thread::yield(); } }); thread t9([PERIOD, &counter, &start, &go, &pool] { // test std::function<> of void() while (!go.load(memory_order_acquire)) std::this_thread::yield(); std::function<void()> task = static_cast<void(*)()>(shoot); for (counter[9] = 0; steady_clock::now() - start <= PERIOD; ++counter[9]) { pool.submit(task); std::this_thread::yield(); } }); thread t10([PERIOD, &counter, &start, &go, &pool] { // test std::function<> of bool(size_t) while (!go.load(memory_order_acquire)) std::this_thread::yield(); std::function<bool(size_t)> task = static_cast<bool(*)(size_t)>(shoot); for (counter[10] = 0; steady_clock::now() - start <= PERIOD; ++counter[10]) { future<bool> r = pool.submit(std::bind(task, counter[10])); std::this_thread::yield(); } }); ...... }折叠
编译代码(-std=c++11)成功后运行可执行文件。以下是执行过程中的部分输出, ... [Functor] Let an arrow fly... [Free Function] Let 9224 arrows fly... [Free Function] Let 9445 arrows fly... [Member Function] Let 9375 arrows fly... [Lambda] Let 9449 arrows fly... [Free Function] Let an arrow fly... [Lambda] Let an arrow fly... [Member Function] Let an arrow fly... [Functor] Let 9469 arrows fly... ...
◆ 最后完整的代码请参考 [github] cnblogs/15592234/ 。 写作过程中,笔者参考了 C++并发编程实战 / (美)威廉姆斯 (Williams, A.) 著; 周全等译. - 北京: 人民邮电出版社, 2015.6 (2016.4重印) 一书中的部分设计思路。致 Anthony Williams、周全等译者。 受限于作者的水平,读者如发现有任何错误或有疑问之处,请追加评论或发邮件联系 15040298@qq.com。作者将在收到意见后的第一时间里予以回复。 本文来自博客园,作者:green-cnblogs,转载请注明原文链接:https://www.cnblogs.com/green-cnblogs/p/15592234.html 谢谢! | 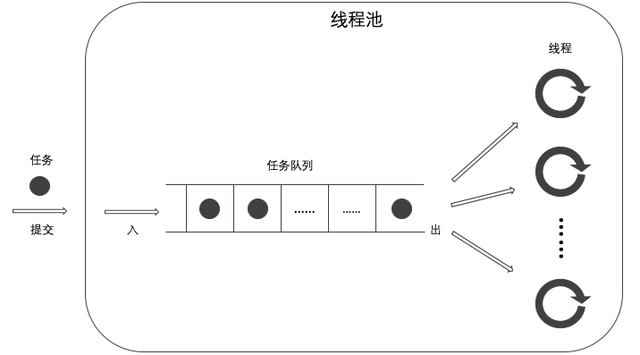

 /1
/1 
 |手机版|免责声明|本站介绍|工控课堂
( 沪ICP备20008691号-1 )
|手机版|免责声明|本站介绍|工控课堂
( 沪ICP备20008691号-1 )